In Adam Harvey's Stratosphere of Surveillance Team Obfuscation were prompted to counter-surveil or obfuscate the form of surveillance which Team Data was challenged to implement. Reverse engineering an approach to a pre-existing technology is a dynamic and easier place to come from as any system has it's brittle points/vulnerabilities.

FAMILY VALUES: A RECURSIVE DATA OBJECT AS COLLAPSED PORTRAIT
This is a JSON object representing me as my family and certain basic 'values' which are closely tracked by the US government. This is a 'speculative' data architecture which I suggest likely exists or will exist soon in a similar form. In addition, I propose data objects like this will be assigned to every human being on the planet.
I presented this image as my Stratosphere of Surveillance course midterm along with my research on two projects involving the CDC, the Social Security Administration, and the International Statistics Program.
Here are the project links:
CDC, NCHS, SSA, Medicaid, Medicare, and the Renal Registry link vital statistics and health data for "poor, elderly, disabled" populations and to promote "safer, healthier, people"
http://www.cdc.gov/nchs/isp/isp_fetp.htm
"A Training Course on Civil Registration and Vital Statistics Systems" to help countries all over the world register marriage and birth statistics and international diagnosis codes (ICD10) for cause of death:
http://www.cdc.gov/nchs/data/series/sr_01/sr01_058.pdf*
*note: In roughly 200 training slides only three mentioned confidentiality of health and vital statistics as being an "ideal" concern and none were instructive on how to ensure confidentiality in practice.
These cross-agency and cross-government vital and health statistics linkage projects are vital for helping vulnerable populations. I propose that they also expose vulnerable populations to certain sociological risks.
See this enlightening quote from UNESCO on the origins of archiving and data collection for more on the connection I make between these two government projects and this combined 'portrait' of a simple yet powerful 'surveillance tool', the agencies that use it, and its subject :
The reasons why records and archives where kept where very much clear. To prove your right to the possession of a certain piece of land you needed title deeds; to determine the size of a population being governed and therefore the taxes that should be collected you required records of birth and death; to enforce government laws and regulations it was necessary to keep a record of the laws, decrees and edicts. The keeping of records and archives was therefore not a luxury but a necessity on which depended one's ability to continue to rule and to have rights and privileges. The records and archives were also preserved in order to prove the rights and privileges of those being governed.
http://www.unesco.org/webworld/ramp/html/r9008e/r9008e03.htm

It is easy to see that the form of this data object reflects its contents: a family tree. The code for 'drilling' into this data architecture is just a few lines. My overarching intention is to show how simple it is to place disparate data, once collected, into an object which can be used to create historical and predictive models of things as complex and weighty as the shape of all of humanity. There are around 5000 generations in human history. That is roughly 15 Megabytes of data per individual using this JSON as a yardstick.
Imagine if this kind of concertina'd data structure could be appended to include ancient data such as the records systematically collected by the Roman Empire. Imagine if that data, current data, and our children's data were to be collected and stored together in this data architecture for one thousand, or ten thousand years from now as current state of the art storage and processing technologies will allow. http://news.discovery.com/tech/biotechnology/dna-data-storage-lasts-thousands-of-years-150817.htm. (An interesting note also with digital DNA data storage: it cannot be accessed and read by specific indices - all of the data stored by this method must be read at once and then re-written all at once which also supports the conceptual affect of this kind of recursive object.) As sophisticated as online, mobile, and social network tracking and surveillance continues to become - this kind of basic foundational data must be organized in order to maximize more sophisticated data around the global population as different factions shift their economic stature.
This project links to other work I did in Art Kleiner's Future of New Media class in Spring 2015 and Chris Woebken and Richard The's Testing Tomorrow's class earlier in Fall 2015. This project also plays into world-building for my thesis project which is a science fiction screenplay about an AI who discovers the answer to saving humanity and biodiversity. This fiction acts as a kind of love letter to the complete faithfulness to purpose which captivated audiences in T1 + T2, as well as to the ancestral aspects of Dune (Lynch , 1985), and Neuromancer.

ARTIFACTS FROM A LEGAL ENVIRONMENT FOR A NEW AMERICAN ECONOMY
For my Stratosphere of Surveillance Midterm I am creating a rationalist speculative fiction regarding the current and plausible future of massive data collection driven by private interests in conjunction with the failures of Capitalism and globalization.
STORYTELLING ELEMENTS
a facsimile of a federal statute, bill, and/or ruling referencing
the 2016 Supreme Court decision which ruled that all data generation qualifies as compensable labor
and
registered US and multinational corporations doing trade in the United States must submit to regulation by a newly formed body
a speculative JSON file and/or code snippet which shows the infamous 'recursive french braid' architecture which creates a cohesive, stable database for predictive and deep historical modeling through intergenerational tracking of every human on earth.
which would contain an ASCII version of the human-writeable, machine-readable identifier-authenticator tattoo design which references matrilineal descent
and
the DNA digital data storage translation (the method which converts the information to base code pairs GACT for final storage by oligonucleotide synthesis machines
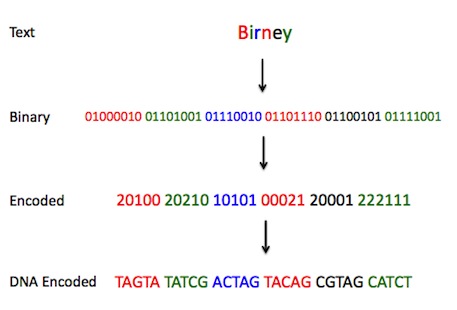
http://nextgenseek.com/2012/08/next-gen-digital-data-storage-goes-dna/
TYPES OF DATA COLLECTED
- currency is de-anonymized and retains transactional history with ID
- familial relations
- genealogy and historical socioeconomic status
- intergenerational social networks
- dna and epigenetics
- telecommunications
- purchases of goods
- credit history
- educational records
- social network sentiment analysis
- biometrics
- endocrine status
- health records
- footstep trajectory
- sleep schedule/circadian rhythm
- sexual relations, schedule, fertility
- microbiome
- familial political sentiment
- information queries (Google, library card history, interpersonal questioning inflected utterances)
- infrared emotional heat mapping
- energy use (various types/via various devices and situations, individually, and in aggregate)
- responses to advertisements and prompts
- emotional responses and interaction patterns to media (movies, texts, music)
HOW DATA IS COLLECTED
Wherever possible data is collected subtly but not surreptitiously
- phone/telecommunication device microphones
- accelerometer and gyroscope
- PIR
- GPS
- publicly-situated smart devices equipped with microphones
- man-in-the-middle web traffic routing
- fingerprinting physical monetary tender
- active questioning (voluntary divulgence)
HOW THE DATA IS USED
OTHER LOGISTICAL DETAILS OF WORLD-BUILDING
RESEARCHES + INSPIRATIONS
IBM WATSON
June 2015 — IBM today sent a letter commending Senators Orrin Hatch and Christopher Murphy for the leadership in advancing legislation that would give non-U.S. citizens greater insight into how their lawfully-collected data is being used and to address errors as they arise.
http://ibmtvdemo.edgesuite.net/software/government/pdf/20150624_JudRedressAct_Ltg_Senate_Signed.pdf
ENIGMA.io
CAPTIALISM, SEC, LEGAL CODE
http://uscode.house.gov/view.xhtml?path=/prelim@title15&edition=prelim
IRL EXAMPLES OF UBIQUITOUS DATA COLLECTION SYSTEMS
"LinkNYC is the largest and most advanced outdoor digital advertising platform in the world. As a city-wide network with thousands of screens on top of an Internet and data-rich backbone, brands and organizations have the opportunity to reach both mainstream and hyperlocal audiences in support of a valuable public service [sic: access to the Internet]. This egalitarian new platform blurs the lines between digital and physical, and the opportunities for civic, commercial, and cultural engagement are endless."
http://www.link.nyc/advertise.html
"Signals are transmitted from the balloons to a specialized internet antenna mounted to the side of a home or workplace, or directly to LTE-enabled devices. Web traffic that travels through the balloon network is ultimately relayed to our local telecommunications partners' ground stations, where it connects to pre-existing Internet infrastructure."
https://www.google.com/loon/faq/
"The goal of Project Loon is to bring internet access to the 2 out of 3 people who don't have internet access today"
https://plus.google.com/+ProjectLoon/videos
PRESENTATION
I'd

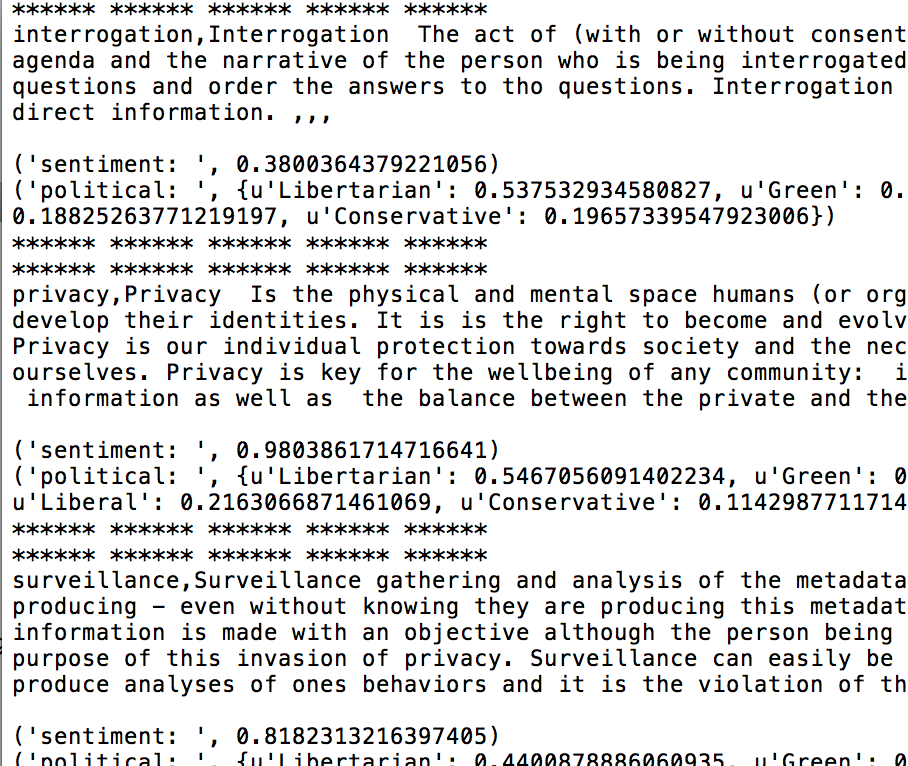
Indico.io API + text analysis of definitions: privacy, surveillance, interrogation
Interesting introduction to thinking a bit more deeply about how algorithms are engineered to learn about sentiment and meaning analysis. This small CSV data set was a set of definitions of 'privacy', 'surveillance', and 'interrogation'.
I analyzed each definition as a line using the Indico API for "political analysis" and also "sentiment." They seem pretty arbitrary but I suppose they gather the information from tags and things like that - but I think a point to explore further is: the internet is quite two-dimensional as a way to gather understanding of complex human sentiment and issues and tropes with a spatio-temporal history. If AIs are the children of humanity - is that any way to teach a child? Come now.
It is fun to play with the browser/GUI version and run words like "God" or "visage" or "face" or "help" (100% positive sentiment analysis) or "hurt" (1% sentiment analysis) though. https://indico.io
I just used some ngram examples I worked with a little in Python from Spring 2015's Python-based course Reading and Writing Electronic Text. I dabbled a bit in using the API to analyze each definition in a row as a line. Then I also analyzed each individual word which showed up more than twice in the text.